Unsere vernetzte Welt verstehen

Wieso entsteht Bias in unseren Sprachtechnologien?
Warum enthalten Übersetzungsprogramme oder Chatbots auf unseren Computern oft diskriminierende Tendenzen gegenüber wie Geschlecht oder Herkunft? Hier ist ein einfacher Leitfaden um Bias in Sprachtechnologien zu verstehen. Wir erklären, wie die Verarbeitung natürlicher Sprache funktioniert und warum sexistische Technologien wie Suchmaschinen nicht nur ein unglücklicher Zufall sind.
Was ist Bias in Übersetzungsprogrammen?
Hast Du schon mal maschinelles Übersetzen benutzt, um einen Satz ins Estnische zu übersetzen? Diese, wie auch andere Sprachen, nutzen kein grammatikalisches Geschlecht Artikel und Substantive lassen keine Rückschlüsse auf das Geschlecht zu. Bei der Übersetzung muss die Software eine eigene Entscheidung treffen. Diese Entscheidung orientiert sich aber häufig an Klischees. Ist das nur Zufall?
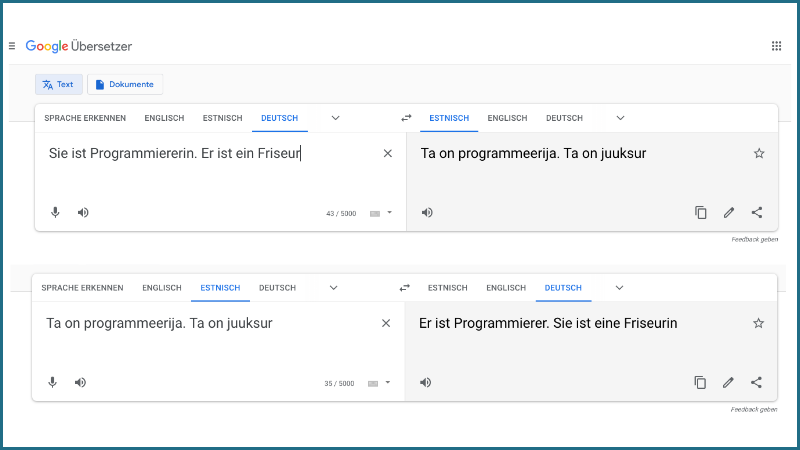
Moderne Übersetzungsprogramme werden auf Basis von riesigen Mengen von Sprachdaten erstellt: Und diese aus dem Alltagsgebrauch entnommenen Sprachdaten haben häufig einen Bias. Unter Bias verstehen wir eine systematische und ungerechte Diskriminierung eines Indiviuums oder einer Gruppe von Individuen zugunsten anderer. Die Art und Weise, wie diese Systeme erstellt werden, kann sogar zu einer Verstärkung dieses Bias führen.
Wie lernen solche Systeme? Wir werden mit einer technischen Erklärung beginnen, wie Wörter mit Zahlen repräsentiert werden – sogenannte Worteinbettungen -, sodass sie von Computern verstanden werden können. Wir wollen damit nicht langweilen, sondern klarmachen, dass Bias in Worteinbettungen kein Zufall, sondern ein logisches Nebenprodukt ist. Im Anschluss diskutieren wir die Folgen verzerrter Einbettungen an einem Praxisbeispiel.
Was sind Worteinbettungen und wieso benutzen wir sie?
Worteinbettungen sind zunächst nichts anderes als Zahlenlisten. Wenn Du Google nach dem Wort “women” durchsuchst, sieht das Programm eine Liste aus Zahlen und berechnet die Ergebnisse auf dieser Grundlage. Computer können Wörter nämlich nicht direkt verarbeiten, deswegen braucht es Einbettungen.

Wichtig ist, Wörter auf eine Weise in Zahlen zu übersetzen, dass möglichst wenig Information verloren geht. Wir könnten beispielsweise einfach Durchzählen, wie im Beispiel unten. Jedes Wort wird durch eine Zahl repräsentiert. Bei diesem Vorgehen bleibt die Information erhalten, dass sich manche Wörter wiederholen, denn denselben Wörtern werden dieselben Zahlen zugeordnet.
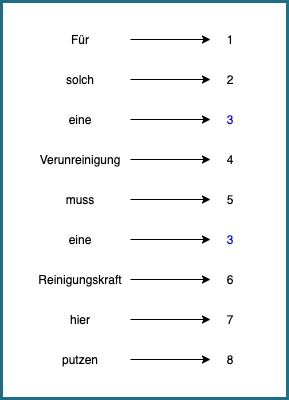
Aber da geht noch mehr. “Verunreinigung”, “Reinigungskraft” und “Putzen” sind in gewisser Hinsicht ähnliche Begriffe. Wir wollen, dass sich diese Ähnlichkeit auch in den Einbettungen spiegelt. Dafür braucht es noch cleverere Methoden.
Worteinbettungen und maschinelles Lernen
Wir fokussieren uns auf eine bestimmte Einbettungstechnik, nämlich GloVe. GloVe gehört zur Klasse des maschinellen Lernens. Das heißt, dass wir diesmal nicht manuell Zahlen zuweisen, sondern die Einbettung mittels eines riesigen Sprachkorpus lernen (und mit riesig meinen wir Milliarden von Wörtern).
Dieser Satz bringt die Idee hinter GloVe auf den Punkt: “Du sollst ein Wort an der Gesellschaft erkennen, die es umgibt.” Das heißt nichts anderes, als dass der Kontext eines Wortes schon sehr viel über dessen Bedeutung preisgibt. Kaschiert man Worte des vorigen Satzes, könnte man sie immer noch grob erraten: “Für solch eine ___ muss eine Reinigungskraft hier putzen.” Der GloVe Algorithmus besteht aus drei Schritten:
- Zunächst ziehen wir eine Art Fenster über unseren Korpus. Das Fenster repräsentiert den Kontext, wobei dessen Größe experimentell zu bestimmen ist. Es gibt Experimente, die zeigen, dass bei einer Fenstergröße von 2 beispielsweise “Hogwarts” stärker mit anderen fiktiven Schulen wie “Sunnydale” oder “Evernight” assoziiert wird, bei einer Größe von 5 jedoch mit Wörtern wie “Dumbledore” oder “Malfoy”.
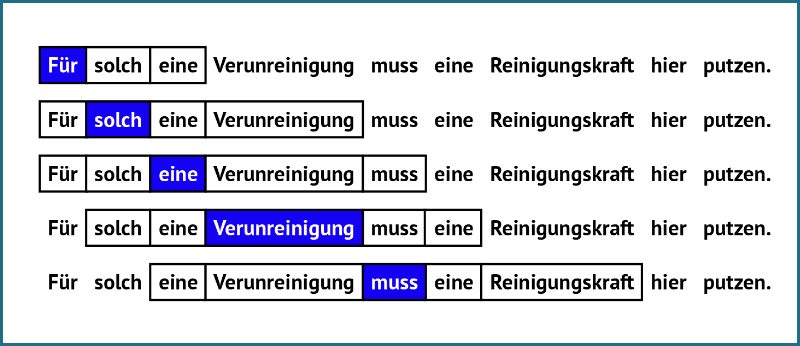
- Als zweites zählen wir das gemeinsame Auftauchen der Wörter. Wörter tauchen gemeinsam auf, wenn sie in dasselbe Fenster passen, wie z.B. “Verunreinigung” mit “solch”, “eine” und “muss”. Das Resultat kann wie folgt dargestellt werden.
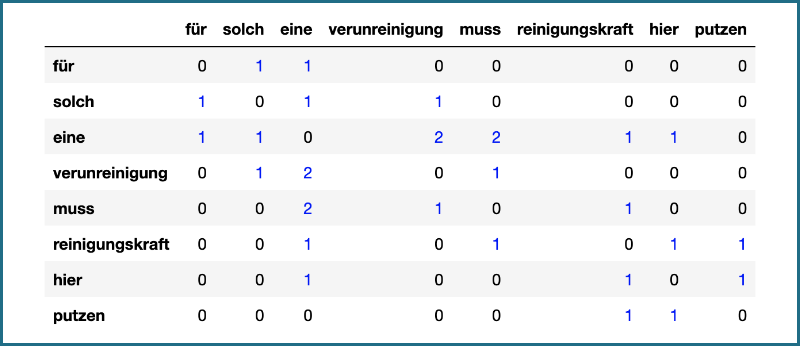
- Der dritte Schritt ist nun das eigentliche Lernen an den Daten (Wir werden nicht zu sehr ins Detail gehen, denn das setzt versierte mathematische Kenntnisse voraus.) Die zugrundeliegende Idee ist aber recht simpel. Erst berechnen wir die Wahrscheinlichkeiten des gemeinsamen Auftauchens. Wörter, die häufig zusammen auftauchen, wie “Verunreinigung” und “Reinigungskraft”, werden eine hohe Wahrscheinlichkeit zugewiesen, seltenen Paaren, wie “Reinigungskraft” und “Elephant” eine niedrige. Zuletzt weisen wir den Wörtern auf Basis dieser Wahrscheinlichkeiten ihre Einbettungen zu. Die jeweiligen Zahlenlisten für “Verunreinigung” und “Reinigungskraft” werden sich ähneln und sehr verschieden sein von der für “Elephant”.
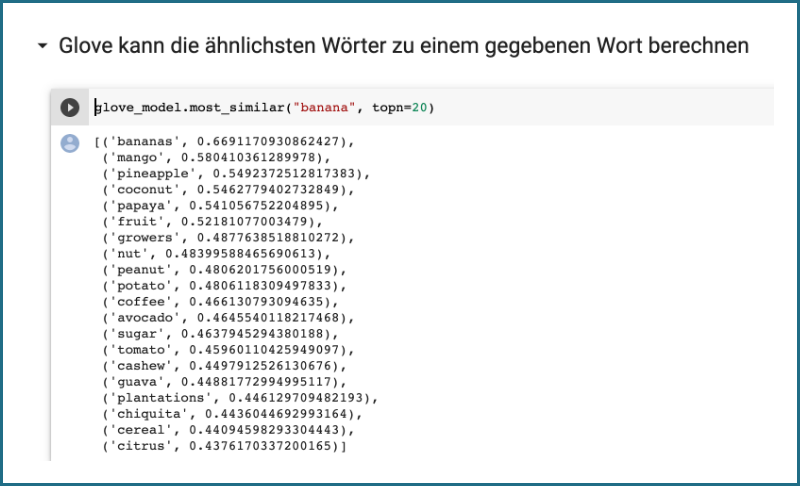
Das wars! Das sind alle Schritte der GloVe Einbettungen. Der gesamte Vorgang besteht daraus, ein Fenster über Millionen von Sätzen aus dem Internet zu ziehen, das gemeinsame Auftauchen zu zählen, die Wahrscheinlichkeiten zu berechnen und die Einbettungen entsprechend zuzuweisen.
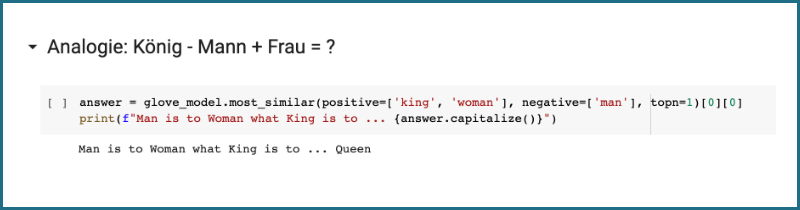
GloVe wird zwar in den meisten modernen Technologien nicht mehr verwendet und ist durch etwas fortschrittlichere Methoden ersetzt worden, aber die zugrundeliegenden Prinzipien sind dieselben: Ähnlichkeit (und Bedeutung) werden auf der Grundlage des gemeinsamen Auftauchens zugewiesen.
Bias in Sprachtechonlogien: Nur ein Hirngespinst?
Aber zurück zum ursprünglichen Thema: Was macht diese Methode so anfällig für Bias? Stell dir vor, dass Wörter wie “Putzkraft” häufig gemeinsam mit “Frau” oder “Ingenieur” mit “Mann” auftauchen. GloVe wird auch diesen Paaren eine starke Ähnlichkeit zuordnen. Und das ist ein Problem: Bias in Worteinbettungen ist kein Zufall. Der gleiche Mechanismus, der ihnen die Fähigkeit verleiht, die Bedeutung von Wörtern zu erfassen, ist auch für Bias bezüglich Geschlecht, Herkunft etc. verantwortlich.
Worteinbettungen befinden sich an der Basis der meisten modernen Systeme, inklusive der Technologien, die wir täglich benutzen. Von Suchmaschinen über Sprach- und Texterkennung bis hin zu Übersetzungsprogrammen, Einbettungen bilden die Grundlage von alledem. Und wenn die Grundlage einen Bias hat, dann ist es nicht unwahrscheinlich, dass dieser auf das gesamte System überspringt. Aber ist dieser Bias nur ein theoretisches Problem oder hat es auch Auswirkungen auf die reale Welt?
Männlich-trainierte Worteinbettungen fördern diskriminierende Tendenzen
Tippt man “maschinelles Lernen” in eine Suchmaschine ein, erhält man tausende Treffer –zu viele, um sie sich alle anzusehen. Sie müssen also nach Relevanz sortiert werden. Aber wie bestimmt man, was relevant ist? Es hat sich herausgestellt, dass Worteinbettungen und das Sortieren nach Ähnlichkeit eine gute Lösung ist. Wörter, die ähnlich zu “machinelles Lernen” sind, werden nach oben sortiert. Allerdings hat sich auch gezeigt herausgestellt, dass Worteinbettungen oft einen Gender Bias haben. Stell dir vor, Du suchst nach “Informatik Promovierende an der Humboldt Universität”. Was passieren kann, ist, dass dir die Webseiten männlicher Promovierender ganz oben angezeigt werden, weil deren Namen stärker mit “Informatik” assoziiert werden. Und das wiederum kann den Eindruck verstärken, dass es keine oder weniger Frauen in der Informatik gibt.
Vielleicht ist es keine Überraschung, dass Einbettungen einen Bias entwickeln, wenn man sich anschaut, womit sie gefüttert werden. Die Trainingsdaten von GPT-2, einem der größten Sprachmodelle, wurde über ausgehende Links von Reddit bezogen. Diese werden hauptsächlich von Männern zwischen 18 und 29 angelegt. Es gibt aber auch Einbettungen, die an Wikipedia Einträgen – einer vermeintlich Bias-freien Quelle – trainiert wurden. Und doch entwickelten sie einen Bias. Das könnte daran liegen, dass nur etwa 18 % der Biografien in der (englischen) Wikipedia über Frauen und nur 8-15 % der Beiträge von Autorinnen verfasst wurden. Die Wahrheit ist, dass es ziemlich schwierig ist, große ausgewogene Sprachdatensätze zu finden.
Wir könnten noch mehr und mehr und mehr und mehr Beispiele aufzeigen, aber wir werfen den Blick lieber auf etwas Optimistisches: Lösungen!
Was können wir also gegen Bias in Sprachtechnologien tun?
Sprachbasierte Technologie ist oft rassistisch, sexistisch, ableistisch, altersdiskriminierend etc. Aber es gibt auch den schwachen Schimmer einer guten Nachricht: Wir können etwas dagegen tun! Noch besser: Das Bewusstsein, dass diese Probleme existieren, ist bereits der erste Schritt. Zusätzlich können wir auch versuchen, einen Datensatz zu erstellen, der von vornherein weniger Bias enthält.
Da dies so gut wie unmöglich ist, da linguistische Daten immer bereits vorhandenen Bias enthalten, besteht eine Alternative darin, den Datensatz genau zu beschreiben. Auf diese Weise können sowohl Forschung als auch Industrie sicherstellen, dass sie nur geeignete Datensätze verwenden, und sie können gründlicher abschätzen, welche Auswirkungen die Verwendung eines bestimmten Datensatzes in einem bestimmten Kontext haben wird.
Auf technischer Ebene gibt es verschiedene Techniken, um Bias im eigentlichen System zu verringern. Einige dieser Techniken beinhalten die Beurteilung der Angemessenheit einer Unterscheidung. Zum Beispiel ist die geschlechtsspezifische Unterscheidung zwischen “Mutter” und “Vater” angemessen, während “Hausfrau” und “Programmierer” eher unangemessen sind. Die Worteinbettungen für diese unpassenden Wortpaare werden dann entsprechend angepasst. Wie erfolgreich diese Methoden in der Praxis tatsächlich sind, ist umstritten.
Grundsätzlich sollten die Menschen, die von einer Technologie potenziell betroffen sind – insbesondere die negativ Betroffenen – im Mittelpunkt der Forschung stehen. Und dazu gehört ihre Einbeziehung in alle Phasen des Entwicklungsprozesses – je früher, desto besser!
Vorsicht mit den Daten und probiers mit Partizipation
Vorurteile, die in unserer Gesellschaft bestehen, spiegeln sich in der Sprache, die wir verwenden, wider. Und dies kann durch Sprachtechnologien sogar noch verstärkt werden. Als Mindestanforderung sollten Technologien, die kritische Entscheidungen treffen – wie ein System, das automatisch entscheidet, ob ein Kredit gewährt wird oder nicht – partizipativ gestaltet werden. Und zwar vom Anfang bis zum Ende des Entwicklungsprozesses. Nur, weil Menschen diskriminierend sein können, heißt das nicht, dass Computer das auch sein müssen! Es gibt Werkzeuge und Methoden, um die Auswirkungen zu verringern. Und wir können Worteinbettungen sogar zur Erforschung von Bias verwenden. Also: Sei dir bewusst, welche Daten Du verwendest, probier technische Methoden zum Abbau von Bias aus und integriere stets die verschiedenen Interessengruppen.
Dieser Beitrag spiegelt die Meinung der Autorinnen und Autoren und weder notwendigerweise noch ausschließlich die Meinung des Institutes wider. Für mehr Informationen zu den Inhalten dieser Beiträge und den assoziierten Forschungsprojekten kontaktieren Sie bitte info@hiig.de

Freya Hewett

Sami Nenno

Jetzt anmelden und die neuesten Blogartikel einmal im Monat per Newsletter erhalten.

Künstliche Intelligenz und Gesellschaft

KI am Mikrofon: Die Stimme der Zukunft?
Von synthetischen Stimmen bis hin zu automatisch erstellten Podcast-Folgen – KI am Mikrofon revolutioniert die Produktion digitaler Audioinhalte.

Haben Community Notes eine Parteipräferenz?
Dieser Artikel analysiert, ob Community Notes Desinformation eindämmen oder ob ihre Verteilung und Bewertung politische Tendenzen widerspiegeln.

Wie People Analytics die Wahrnehmung von Fairness am Arbeitsplatz beeinflusst
People Analytics am Arbeitsplatz kann die Beziehung und das Vertrauen zwischen Mitarbeitenden und Führungskräften beeinflussen.