
Menschenzentrierte Data Governance im Gesundheits- und Pflegesektor
Auch wenn Akteure durch gemeinsame Werte und Ziele verbunden sind, können sie unterschiedliche Vorstellungen, Interessen und Risikowahrnehmungen hinsichtlich des Umgangs mit schützenswerten Daten haben. Diese Vorstellungen müssen zusammengeführt und die widerstreitenden Interessen miteinander in Einklang gebracht werden. Dies erfordert eine gute Data Governance. Wir haben einen kooperativen und inklusiven Data-Governance-Prozess entwickelt, der pragmatisch, zielorientiert und gleichzeitig skalierbar ist.
Einleitung
Wir haben das Digital Urban Center for Aging and Health (DUCAH) als menschenzentriertes Forschungszentrum gegründet, das Lernlabore für transdisziplinäre Perspektiven auf digitale Gesundheit und digitales Altern durchführt. Unsere Vision ist, dass unser Leben, unsere Gesundheit und unser Altern in einer digitalen Gesellschaft individueller, kontextbezogener, datenbasierter, vernetzter, präventiver, menschenwürdiger und gleichzeitig bezahlbarer werden. Wir wollen, dass dies durch intelligente Gesundheitssysteme möglich wird, die den Menschen in den Mittelpunkt stellen und gesunde Nachbarschaften entwickeln. Dies kann mit digitalen und sozialen Innovationen erreicht werden – gemeinsam mit vielen Forschungsdisziplinen, in Kooperation von Staat, Wirtschaft und Zivilgesellschaft. Um dazu beizutragen, werden wir im Rahmen von DUCAH Daten generieren, sammeln und verarbeiten. Dazu gehören auch Gesundheitsdaten, die nach geltendem Datenschutzrecht besonders schützenswert sind.
Auch wenn wir bei DUCAH von gemeinsamen Werten und Zielen angetrieben werden, wie z. B. der menschenzentrierten Gesundheitsförderung, sind wir uns bewusst, dass wir viele unterschiedliche und manchmal widerstreitende Interessen haben, wenn es um den Umgang mit schützenswerten Daten geht. Die DUCAH-Partner sind geprägt von ihren jeweiligen Zielen, Methoden, Prozessen und Strukturen, ihren unterschiedlichen mentalen Modellen und Terminologien, aber auch von ihren unterschiedlichen Auffassungen von Wert und Risiko im Zusammenhang mit der Verarbeitung und Nutzung von Daten. Und Wert und Risiken können sich im Laufe der Zeit ändern, je nachdem, wie die Daten tatsächlich genutzt werden.
Um die Interessen an Daten, ihrer Weitergabe und Nutzung, die zwischen den verschiedenen beteiligten Akteuren in Bezug auf den Wert der Daten und die mit ihrer Verarbeitung verbundenen Risiken divergieren, in Einklang zu bringen, brauchen wir geeignete Data-Governance-Strukturen und -Prozesse. Dies erfordert insbesondere die Berücksichtigung der Kontextabhängigkeit des Wertes und der Risiken von Daten sowie des Einflusses des Rechts auf die Frage, ob Daten auch rechtlich verwertbar sind. Außerdem müssen wir uns auf normativer, organisatorischer und technologischer Ebene abstimmen und ein angemessenes Maß an Zentralisierung oder Dezentralisierung, Standardisierung und Partizipation erreichen. Wir brauchen also einen Governance-Prozess, der skalierbar ist, um sowohl kleine und einfache, d.h. risikoarme, als auch große und risikoreiche Verarbeitungstätigkeiten zu koordinieren. Data Governance muss flexibel sein, wenn sich das gemeinsame Verständnis im Laufe der Verhandlungen ändert, wenn eine Aufteilung in mehrere Verarbeitungstätigkeiten differenziertere Lösungen ermöglicht oder wenn scheinbare „Seitenaspekte“ auftauchen oder Stakeholder Ängste oder Bedenken äußern. Es geht um dezidiert nicht-technokratische Herangehensweisen an Digitalisierungsprojekte, um Ergebnisse zu schaffen, die für alle Beteiligten akzeptabel sind. Und deshalb ist es wichtig, auch das „Warum“ zu klären – warum machen wir dies und nicht jenes, warum ziehen wir diese Option anderen vor –, anstatt auf einen Kommandostil zurückzugreifen.
Ein pragmatisches Prozessmodell für Data Governance
Wir haben einen prozessorientierten Ansatz gewählt, weil wir von der Erkenntnis ausgehen, dass es keine allgemeingültige „Einheitslösung“ gibt. Stattdessen muss ein angemessener Ansatz die konkrete Akteurskonstellation, den Kontext, die Ziele, Interessen, Anliegen und Wünsche der Beteiligten, die konkreten Daten und die technischen Systeme berücksichtigen. Wir haben deshalb im vergangenen Jahr ein Data-Governance-Prozessmodell erarbeitet. Mit diesem Prozess kann eine Lösung für einen konkreten Anwendungsfall entwickelt, gestaltet und implementiert werden, die alle Interessen ausgleicht, alle rechtlichen Anforderungen erfüllt, alle Risiken mindert und die Ziele aller Beteiligten erreicht. Es handelt sich um einen iterativen Prozess, der Flexibilität zulässt, den Input von Expert:innen mit der Einbeziehung von Stakeholdern (Co-Evaluierung, Co-Creation & Co-Design) verbindet und stark lösungsorientiert ist.
Das sechsstufige Prozessmodell
Die folgenden sechs Schritte skizzieren sowohl einen typischen generalisierten Projektablauf als auch den iterativen Teil, der der Identifizierung von Daten, Interessen und die Ableitung von Datenzugriff, -nutzung und -ausgabe dient und den iterativen Charakter unseres Modells widerspiegelt.
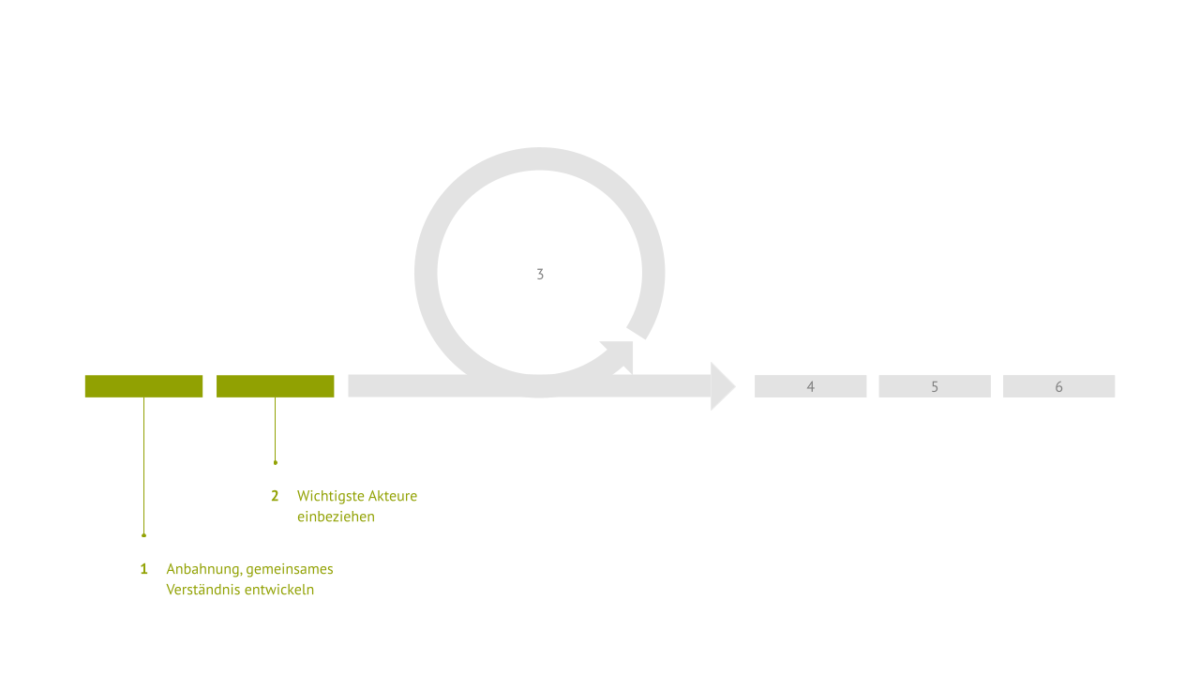
Der erste Schritt besteht darin, alle Initiatoren an einen Tisch zu bringen und ein gemeinsames Verständnis für das Projekt zu finden. Zu diesem Zeitpunkt möchten die Partner möglicherweise eine Kooperationsvereinbarung abschließen und müssen möglicherweise Ethikanträge stellen.
Der zweite Schritt dient der Identifizierung und Einbeziehung aller weiteren notwendigen Stakeholder. Es muss geklärt werden, welche Stakeholder direkt und welche indirekt, z. B. über Vertreter:innen, einbezogen werden müssen und wie geeignete Formate der Einbeziehung für die verschiedenen Stakeholder gestaltet werden müssen. Um eine faire, sinnvolle und ergebnisorientierte Einbeziehung zu ermöglichen, sollten die Formate die Beteiligten, seien es Pflegekräfte, Gepflegte oder Patient:innen, weder geringschätzen noch überfordern.
Der dritte Schritt ist der zentralste und dient der schrittweisen partizipativen Lösungsfindung, die alle drei von uns als notwendig erachteten Dimensionen – die normative, die organisatorische und die technische Dimension sowie deren Zusammenspiel in kombinierten rechtlich-organisatorisch-technischen Lösungen – adressiert. Ziel dieses Schritts ist es, gemeinsam ein konsentiertes Verarbeitungsdesign zu erstellen, das den Interessen, Bedürfnissen und Erwartungen aller Beteiligten gerecht wird. Der dritte Schritt umfasst den inneren Kreislauf, der der prozessorientierten Data Governance die notwendige Anpassungsfähigkeit verleiht.
Die innere Schleife: ein Weg zur iterativen Lösungsfindung
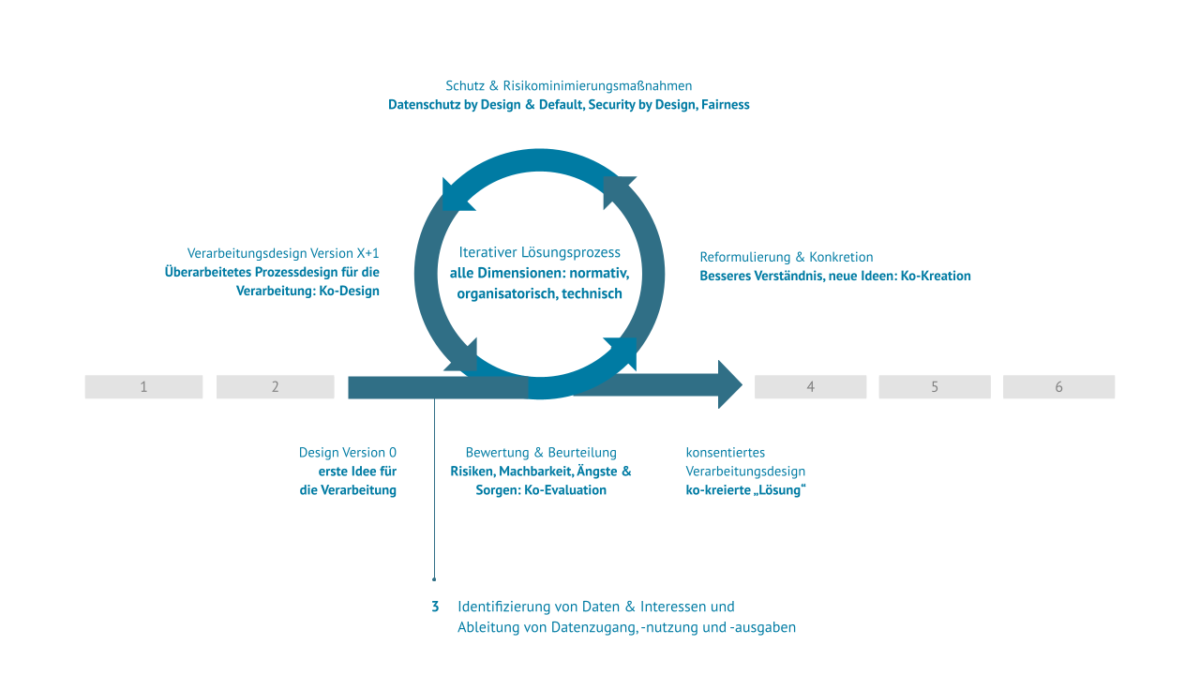
Der iterative Prozess beginnt mit der Entwicklung eines ersten Verarbeitungsdesigns, vielleicht auch nur einer ersten groben Idee, und mit der Klärung der Frage, welche Daten vorhanden sind oder gesammelt werden sollen, welche Ziele erreicht oder welche Erkenntnisse gewonnen werden sollen, und welche technischen Systeme dafür eingesetzt werden sollen.
Dieser erste Verarbeitungsentwurf muss dann bewertet und evaluiert werden: im Hinblick auf die zu erfüllenden oder zu schaffenden Bedingungen, die Durchführbarkeit der Verarbeitung, sowohl in technischer als auch in praktischer Hinsicht, die Auswirkungen und Risiken, die sie mit sich bringen könnte, sowie die Erwartungen, Ängste und Bedenken der Beteiligten. Diese Beurteilung und Bewertung erfordert einen integrativen Ansatz, der alle Beteiligten an einen Tisch bringt, um eine echte Co-Evaluierung zu ermöglichen.
Je nach Ergebnis der partizipativen Bewertung und Evaluierung endet der iterative Prozess entweder mit einem genehmigten Verfahrensentwurf – wenn alle Interessen und Erwartungen erfüllt sind – oder es ist eine weitere Iteration erforderlich: Neuformulierung und Konkretisierung, Schutzmaßnahmen einfügen, Überarbeitung des Verfahrensentwurfs und dann wieder eine partizipative Bewertung und Evaluierung.
Der Schritt der Neuformulierung und Konkretisierung ist stark von Co-Creation-Formaten geprägt und soll den Stakeholdern ermöglichen, einen neuen Blick auf das Verfahren zu werfen, es besser zu verstehen und neue Ideen zu generieren. Oft stellt sich heraus, dass die Beteiligten die gleichen Ziele erreichen können, indem sie über den Tellerrand hinausschauen oder andere Wege einschlagen, und dabei viele Unklarheiten, Bedenken und Risiken lösen, die das bisherige Prozessdesign hervorgerufen hat. Eine wichtige Erkenntnis aus der Praxis ist, dass sich viele Probleme lösen lassen, indem man einen komplexeren und anspruchsvolleren Verarbeitungsentwurf in mehrere, wesentlich weniger komplexe Verarbeitungsentwürfe aufteilt. Diese sind jeweils einfacher zu verstehen, weniger anspruchsvoll, weniger riskant und weniger anfällig für Probleme.
Einbindung von Fachwissen
Der nächste Schritt im iterativen Prozess, die Integration von Schutzmaßnahmen, besteht dann darin, auf Fachwissen aus verschiedenen Bereichen und Disziplinen zurückzugreifen, um Maßnahmen in das Verarbeitungsdesign einzuarbeiten, die die Einhaltung aller geltenden Gesetze, den Schutz aller Beteiligten und ihrer Rechte und Interessen sowie die Minimierung von Risiken und unerwünschten Auswirkungen der Verarbeitung gewährleisten. Dieses Fachwissen sollte Themen wie Informations- und Cybersicherheit, Datenschutz („by Design“ und durch Voreinstellung) und andere Rechtsbereiche sowie Transparenz, Fairness und Erklärbarkeit bei KI und Algorithmen umfassen.
Auf der Grundlage der Neuformulierung und Konkretisierung sowie der Integration von Schutzmaßnahmen ist das Verarbeitungsdesign zu überarbeiten und neu zu gestalten. Auch in dieser Phase ist ein inklusiver, partizipativer Ansatz mit geeigneten Co-Design-Formaten erforderlich.
Dieses überarbeitete Verarbeitungsdesign muss dann wiederum bewertet und evaluiert werden – und je nach Ergebnis kann der iterative Prozess erneut beginnen. Abgesehen von einigen wenigen risikoreichen Verarbeitungen, die mehrere Durchläufe dieses iterativen Prozesses erfordern, wissen wir sowohl aus der Forschungsliteratur als auch aus praktischer Erfahrung, dass selten mehr als zwei Durchläufe erforderlich sind, bis das Verarbeitungsdesign den Interessen, Bedürfnissen und Erwartungen aller Beteiligten entspricht.
Die abschließenden Schritte des pragmatischen Data-Governance-Prozessmodells
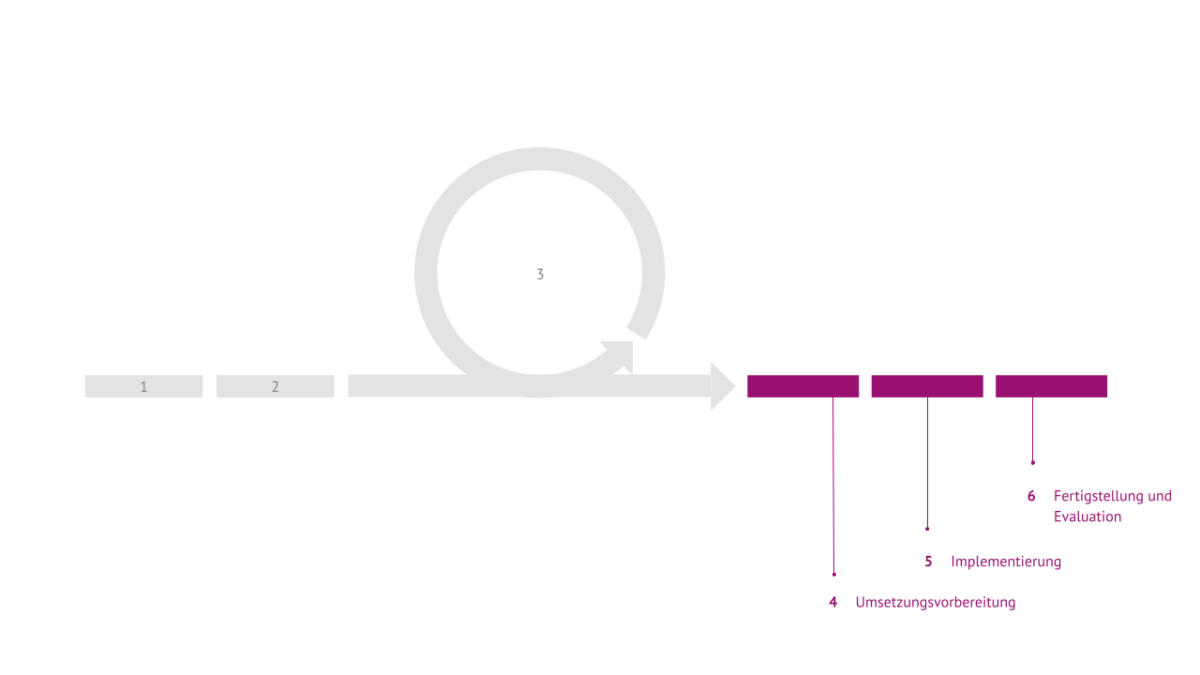
Der vierte Schritt baut auf dem konsentierten Verarbeitungsdesign auf und zielt darauf ab, die erfolgreiche Durchführung des Projekts vorzubereiten. Dazu gehören die Erstellung von geeignetem Informationsmaterial, die Ausarbeitung von Verträgen, z. B. mit Unterauftragnehmern, und Einverständniserklärungen, vielleicht auch die Vorbereitung und Einreichung gemeinsamer Drittmittelanträge, auf jeden Fall aber die gemeinsame Abstimmung von Arbeits- und Zeitplänen. Wenn alles fertig ist, kann das Projekt beginnen.
Der Data-Governance-Prozess endet nicht mit Projektstart, sondern begleitet das Projekt auch in der Implementierungs- und Ausführungsphase. Der fünfte Schritt umfasst u.a. mögliche Einführungs- oder Begleitworkshops für die verschiedenen Akteure. Vor allem aber geht es darum, dass die Datenerhebung, -verarbeitung und -nutzung begleitet wird und dass auftretende Fragen und Herausforderungen rechtzeitig angegangen werden, bevor sie zu Problemen werden können.
Gemeinsames Lernen für zukünftige Projekte
Nach Abschluss des Projekts ist der sechste und letzte Schritt der Abschluss des Data-Governance-Prozesses, die Bewertung und das gemeinsame Lernen für zukünftige Projekte und die begleitende Data Governance. Dazu gehören zum Beispiel Abschlussworkshops für die Beteiligten, die wissenschaftliche und praktische Nutzung der Projektergebnisse und die Löschung oder Anonymisierung der gesammelten Daten. Das gemeinsame Lernen aus der Umsetzung des Data-Governance-Prozesses ist enorm wichtig, nicht nur, weil es die Weiterentwicklung des Prozesses selbst ermöglicht, sondern auch, weil es alle Beteiligten befähigt, in Zukunft gemeinsam auch größere und potenziell riskantere Projekte anzugehen. Sie gewinnen dadurch Vertrauen in sich selbst und die anderen Beteiligten, dass sie gemeinsam den Wert der Daten nutzen und Ergebnisse erzielen können, ohne dass ihre Interessen, Bedürfnisse und Erwartungen verletzt werden.
Zum Abschluss
Wir haben das Data-Governance-Prozessmodell bereits erfolgreich in praktischen Anwendungsfällen im Gesundheits- und Pflegesektor getestet. Zum Beispiel in einer Einrichtung der stationären Altenpflege in Zehdenick in Brandenburg. In dieser Einrichtung haben wir ein Messgerät zur Erfassung ergonomischer Daten in Innenräumen aufgestellt und die Data-Governance-Fragen mit dem oben definierten Prozess adressiert. Einige der zentralsten Aspekte des Prozessmodells konnten so bereits validiert werden, zum großen Nutzen der Beteiligten. Dazu gehört die Offenheit, auch scheinbar unbedeutende Aspekte und Anliegen offen, kollegial und produktiv anzusprechen, gerade weil sie von einzelnen Stakeholdern als sehr wichtig erachtet werden können. Dazu gehört auch die Möglichkeit, komplexe Abläufe, für die die Beteiligten keine akzeptable Lösung finden, in mehrere einfachere Prozesse aufzuteilen und jeden davon einzeln zu lösen. Nicht zuletzt haben wir gezeigt, dass der Prozess es ermöglicht, gesetzliche Anforderungen, zum Beispiel aus der EU-Datenschutz-Grundverordnung, überprüfbar umzusetzen.
Wir arbeiten auch weiterhin an der Weiterentwicklung des Prozessmodells, um vor allem die praktische Anwendbarkeit zu verbessern und die Akteure in die Lage zu versetzen, solche Data-Governance-Prozesse auch selbst und ohne externe Anleitung durchzuführen. Dazu arbeiten wir an Leitfragen und Erfolgskriterien für die einzelnen Prozessschritte sowie an der Entwicklung und Integration konkreter Formate für erfolgreiche Co-Evaluation, Co-Creation und Co-Design. Im nächsten Jahr wollen die Autor:innen all dies zusammenführen und ein Praxishandbuch mit konkreten Handlungsempfehlungen zur Verfügung stellen.
Quellen
Jackson, P., Schildhauer, T., Ulich, A., Pohle, J., & Jansen, S. A. (2021). Aging, independent living and technology. Stiftung für Internet und Gesellschaft. DOI: 10.5281/zenodo.5026032 Weitere Informationen
Grafenstein, M. v., & Ulich, A. (2021). Data-Governance-Framework für das Digital Urban Center for Aging and Health (DUCAH). Stiftung für Internet und Gesellschaft. Weitere Informationen
Schildhauer, T., Ulich, A., Winckler, P. (2021). Tech & aging: How to enable independent living with digital innovations. encore, 2021/2022, 160-167. Weitere Informationen
Ulich, A. (2021). Wie wird das digitale Gesundheitssystem fit für die Menschen? Gesundheit, Alter und Data Literacy. In: Renz, A., Etsiwah, B., & Burgueño Hopf, A. T. (eds.), Whitepaper Datenkompetenz. Berlin: Universität der Künste, pp. 27–29. Weitere Informationen

Jörg Pohle, Dr.

Annika Ulich

Maximilian von Grafenstein, Prof. Dr.

Jetzt anmelden und die neuesten Blogartikel einmal im Monat per Newsletter erhalten.

Data Governance

KI am Mikrofon: Die Stimme der Zukunft?
Von synthetischen Stimmen bis hin zu automatisch erstellten Podcast-Folgen – KI am Mikrofon revolutioniert die Produktion digitaler Audioinhalte.

Haben Community Notes eine Parteipräferenz?
Dieser Artikel analysiert, ob Community Notes Desinformation eindämmen oder ob ihre Verteilung und Bewertung politische Tendenzen widerspiegeln.

Wie People Analytics die Wahrnehmung von Fairness am Arbeitsplatz beeinflusst
People Analytics am Arbeitsplatz kann die Beziehung und das Vertrauen zwischen Mitarbeitenden und Führungskräften beeinflussen.