Making sense of our connected world

How to identify bias in Natural Language Processing
Why do translation programmes or chatbots on our computers often contain discriminatory tendencies towards gender or race? Here is an easy guide to understand how bias in natural language processing works. We explain why sexist technologies like search engines are not just an unfortunate coincidence.
What is bias in translation programmes?
Have you ever used machine translation for translating a sentence to Estonian? In some languages, like Estonian, pronouns and nouns do not indicate gender. When translating to English, the software has to make a choice. Which word becomes male and which female? However, often it is a choice grounded in stereotypes. Is this just a coincidence?
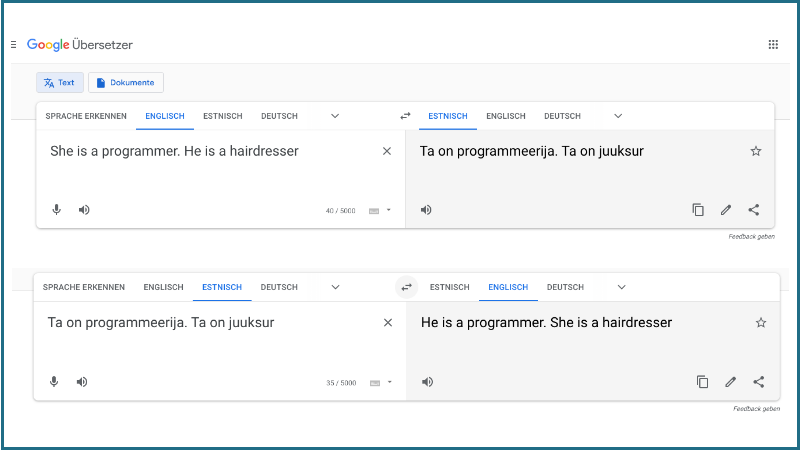
These kinds of systems are created using large amounts of language data – and this naturally occurring language data contains biases: systematic and unfair discrimination against certain individuals or groups of individuals in favour of others. The way these systems are created can even amplify these pre-existing biases. In this blog post we ask where such distortions come from and if there is anything we can do to reduce it?
We will start with a technical explanation of how individual words from large amounts of language data are transformed into numerical representations – so-called embeddings – so that computers can make sense of them. This isn’t to bore you but to make clear that bias in word embeddings is no coincidence but rather a logical byproduct. We will then discuss what happens when biased embeddings are used in practical applications.
Word embeddings: what, why, and how?
Word embeddings are simply lists of numbers. When you search Google for “women”, what the program sees is a list of numbers and the results are based on calculations on those numbers. Computers cannot process words directly. And this is why we need embeddings.

The main goal is to transform words into numbers such that only a minimum of information is lost. Take the following example. Each word is represented by a single number.
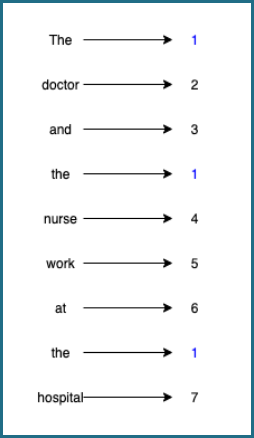
However, we can capture even more information. For instance, “nurse”, “doctor”, and “hospital” are somehow similar. We might want similarity to be represented in the embeddings, too. And this is why we use more sophisticated methods.
Word embeddings and Machine Learning
We will focus on a particular embedding method called GloVe. GloVe falls into the category of machine learning. This means that we do not manually assign numbers to a word like we did before but rather learn the embeddings on a large corpus of language (and by large we mean billions of words).
The basic idea is often expressed by the phrase: “You shall know a word by the company it keeps”. This simply means that the context of a word says much about its meaning. Take the previous sentence again. If we were to mask one of the words, you could still roughly guess what it is: “The ___ and the doctor work at the hospital.” This idea forms the foundation for GloVe and its algorithm consists of three steps.
- First, we sweep a window over a sentence from our language corpus. The size of the window is up to us and depends on how big we want the surrounding context of a word to be. There have been experiments that with a window size of 2 (like below) “Hogwarts” is stronger associated with other fictional schools like “Sunnydale” or “Evernight” but with a size of 5 it is associated with words like “Dumbledore” or “Malfoy”.

- Second, we count the co-occurrences of the words. By co-occurrence we mean the words which appear in the same window as the given word. “Nurse”, for example, co-occurs with “and” and twice with “the”. The result can be displayed in a table.
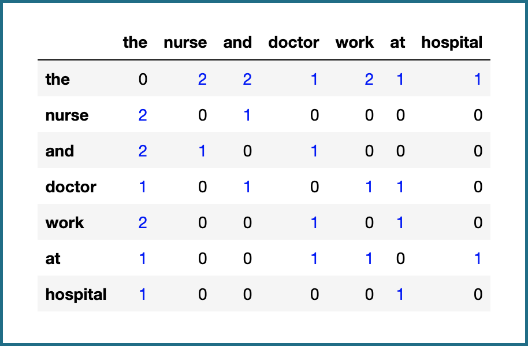
- The third step is the actual learning. We won’t get into detail because this would require a lot of maths. However, the basic idea is simple. We calculate co-occurrence probabilities. Words that co-occur often, such as “doctor” and “nurse”, get a high probability and unlikely pairs like “doctor” and “elephant” get a low probability. Finally, we assign the embeddings according to the probabilities. The embedding for “doctor” and the one for “nurse”, for instance, will have some similar numbers and they will be quite different to the numbers for “elephant”.
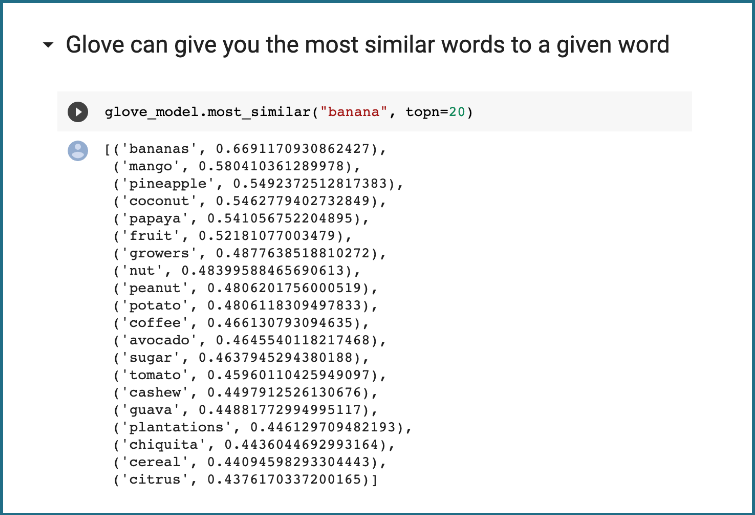
That’s it! Those are all steps needed to create GloVe embeddings. All that was done was to swipe a window over millions of sentences, count the co-occurrences, calculate the probabilities, and assign the embeddings.

Whilst GloVe is not used anymore in most modern technologies, and has been replaced by slightly more advanced methods, the underlying principles are the same: similarity (and meaning) are assigned based on co-occurrence.
Bias in Natural Language Processing: Is it just a fantasy?
But back to the original topic: what is it about this method that makes it so vulnerable to biases? Imagine that words like “engineer” often co-occur with “man” or “nurse” with “woman”. GloVe will assign strong similarity to those pairs, too. And this is a problem. To emphasise this point: bias in word embeddings is no coincidence. The very same mechanism that gives them the ability to capture meaning of words is also responsible for gender, race and other biases.
Bias in embeddings is certainly not cool. But is it merely a theoretical problem or are there also real-world implications? Well, here are some examples to convince you of the latter.
Word embeddings constitute the input of most modern systems, including many ubiquitous technologies that we use daily. From search engines to speech recognition, translation tools to predictive text, embeddings form the foundation of all of these. And when the foundation is biased, there is a good chance that it spreads to the entire system.
Male-trained word embeddings fuel gender bias: It’s real life
When you type “machine learning” into a search engine, you will get thousands of results – too many to go through them all. So you need to rank them by relevance. But how do you determine relevance? As it has been shown, one efficient way is to use word embeddings and rank by similarity. Results that include words similar to “machine learning” will get higher rankings. However, what has been shown, too, is that embeddings are often gender biased. Say, you search for “Computer science PhD student at Humboldt University”. What might happen is that the webpages of male PhD students will be ranked higher because their names are stronger associated with “computer science”. And this in turn reduces the visibility of women in computer science.
Maybe it’s no surprise that these word embeddings grow up to be biased, given what they are fed with. The training data of GPT-2, one of the biggest language models, is sourced by scraping outbound links from Reddit, which is mainly populated by males between the ages of 18 and 29. However, there are also embeddings that have been trained on Wikipedia – a seemingly unbiased source – and yet they turn out to be biased. This might be because only about 18% of biographies on (English) Wikipedia are about women and only 8–15% of contributors are female. Truth is, finding large balanced language data sets is a pretty tough job.
We could go on and go on and go on and go on with examples but let us now turn to something more optimistic: solutions!
So what can we do against bias in Natural Language Processing?
So, the bad news: language-based technology is often racist, sexist, ableist, ageist… the list goes on. But there is a faint glimmer of some good news: we can do something about it! Even better news: awareness that these problems exist is already the first step. We can also attempt to nip the problem in the bud, and try to create a dataset that contains less bias from the offset.
As this is nigh on impossible, as linguistic data will always include pre-existing biases, an alternative is to properly describe your dataset – that way, both research and industry can ensure that they only use appropriate datasets and can assess more thoroughly what impact using a certain dataset in a certain context will have.
On the technical level, various techniques have been proposed to reduce bias in the actual system. Some of these techniques involve judging the appropriateness of a distinction, for example, the gender distinction between ‘mother’ vs. ‘father’ is appropriate, whereas ‘homemaker’ vs. ‘programmer’ rather inappropriate. The word embeddings for these inappropriate word pairs are then adjusted accordingly. How successful these methods actually are in practice is debatable.
Basically, the people who may be affected by a technology – particularly those affected adversely – should be at the centre of research. This also involves consulting with all potential stakeholders at all stages of the development process – the earlier the better!
Watch your data and try participation
Biases that exist in our society are reflected in the language we use; this is further reflected and can even be amplified in technologies that have language as a basis. As a minimum, technologies that have critical outcomes – such as a system that automatically decides whether or not to grant loans – should be designed in a participatory manner, from the beginning of the design process to the very end. Just because people can be discriminatory, this does not mean that computers have to be too! There are tools and methods to decrease the effects and we can even use word embeddings to do research on bias. So: be aware of what data you are using, try out technical de-biasing methods and always keep various stakeholders in the loop.
This post represents the view of the author and does not necessarily represent the view of the institute itself. For more information about the topics of these articles and associated research projects, please contact info@hiig.de.

Freya Hewett

Sami Nenno

You will receive our latest blog articles once a month in a newsletter.

Artificial intelligence and society

Polished yet impersonal: The unintended consequences of writing your emails with AI
AI-written emails can save workers time and improve clarity – but are we losing connection, nuance, and communication skills in the process?

AI at the microphone: The voice of the future?
From synthesising voices and generating entire episodes, AI is transforming digital audio. Explore the opportunities and challenges of AI at the microphone.

Do Community Notes have a party preference?
This article explores whether Community Notes effectively combat disinformation or mirror political biases, analysing distribution and rating patterns.