Making sense of our connected world

Inside Hugging Face
To understand the dynamics of current open-source machine learning research, one platform is of central importance: Hugging Face. For accessing state-of-the-art models, Hugging Face is the place to be. In this post, I analyse how models on this platform changed during the last years and what organisations are active on Hugging Face.
Hugging Face, not OpenAI
While much of recent reporting on AI is focused on OpenAI, the company behind ChatGPT, another company that is much more relevant to the everyday life of a Machine Learning (ML) developer, receives much fewer attention: Hugging Face. Hugging Face is a platform that hosts ML models including Large Language Models (LLMs). Literally everyone can upload and download their models on this platform and it is one of the main drivers for democratising research in ML. Therefore, understanding what actors and models are on Hugging Face, tells us much about current open-source research in ML.
The company behind the emoji
Hugging Face is a young company that was founded in 2017 in New York City. Its original business model was providing a chatbot. However, nowadays it is mostly known as a platform that hosts ML models. At first only language models but in the recent months vision, speech and other modalities were added. Besides free hosting, it also provides some paid services such as a hub to deploy models. Hugging Face is currently rated at two billion dollars and recently partnered with Amazon Web Services.
Models are becoming larger
Contributions to Hugging Face are constantly increasing and repository sizes are growing over time (Fig 1). This means that increasingly large models are uploaded, which mirrors recent developments in AI research. Many of the models are provided by companies, universities, or non-profits but most come from entities that provide no information (“Other”). Manual inspection shows that it includes most often individuals who uploaded one or several models but also organisations that simply did not add their information.

What types of organisations are active on Hugging Face?
Who uploads the largest models and whose models are most wanted? The biggest group in terms of uploaded models is “Other” (Fig 2). The remaining groups, except of “classroom”, are fairly close to each other. This means that universities, non-profits, and companies contribute about equally on Hugging Face.
The recent surge in ML research is mostly driven by Big Tech and elite universities because training large models is extremely resource-intensive in terms of compute and money. Accordingly, one would expect that most large models come from companies or universities and it is also their models that are downloaded the most. But this is only partly the case. Models by companies and universities are most wanted. However, while models uploaded by companies are also relatively large, models by universities are not. The largest models are uploaded by non-profits, however, this is mostly due to a few models by LAION and Big Science, whereas each model is more than hundred gigabytes.

Upload and download are not proportional
What are the individual organisations that contribute the most on Hugging Face? For universities, the University of Helsinki, who provides translation models for various language combinations, is leading by far (Fig 3). However, when it comes to downloads, the Japanese Nara Institute of Science and Technology (NAIST) is leading. This is mostly due to MedNER, their named entity recognition model for medical documents that is also among the top 10 of the most downloaded models on Hugging Face. German universities are among the organisations with the highest model count but also the most downloads.
The non-profit repositories with the most models should not be trusted too much, since three of them are entertained by a single PhD student. However, the organisations in this category with the highest download rate are well-known non-profit organisations like LAION and BigCode, that contribute a lot to the open-source community.
Little surprising, Big Tech companies lead the industry category with respect to upload counts. However, it is neither Google nor Facebook who have the highest download rate but Runway with their Stable Diffusion model.
The top 10 of most downloaded models is led by Wave2Vec, a speech recognition model. It is surprising that even though Hugging Face was long known as a platform for unimodal language models, many of the most downloaded models are bimodal for text and either vision or speech.

Open-source LLMs are on the rise
Latest since the launch of ChatGPT, LLMs found their way into public attention. However, in line with a recently leaked Memo from a Google-developer, open-source is becoming a serious competitor for LLMs. Hugging Face started a leader board for open LLMs and some of them reach performance close to ChatGPT.
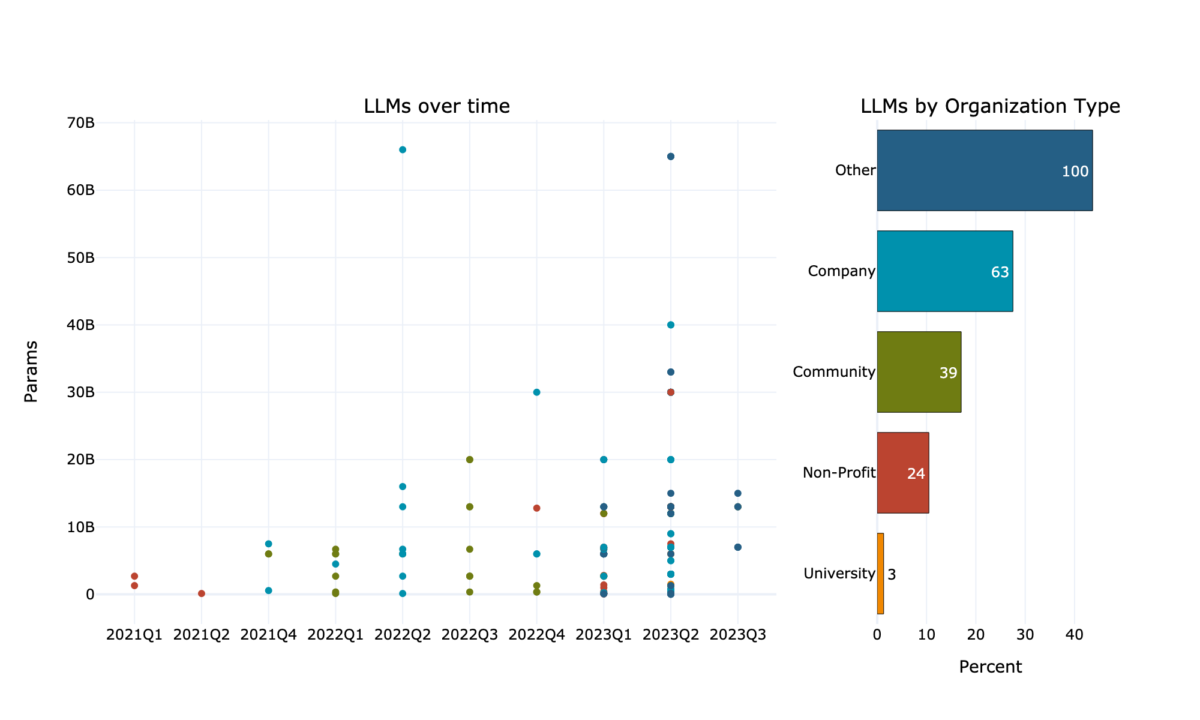
Model size, measured in Parameters, increased in recent years drastically (Fig 4). While in 2021 only few models reached 3 billion parameters, currently there are many more and larger open models, reaching almost 70 billion parameters.
The organisation type that uploads the most LLMs is “Other”. However, this is mostly driven by a few actors, who uploaded sometimes even more than 15 models each. The group that uploads the second most LLMs are companies and they upload LLMs with an average of 10 billion parameters. Universities on the other side do not only upload the fewest LLMs but also the smallest on average.
Large models, large emissions. Small models, small emissions
Good news first: training most of the models emitted less CO2 than streaming in 4K quality for one hour. The bad news is that only a bit more than 1% of the models at Hugging Face provide this information. 1706 of these 1846 models that include emission information are from “Other”. However, 99.5% of the emissions come from Non-Profit models. This means that training only a few models lead to the biggest share of emissions. This emphasises that the major part of emissions comes from large projects and not from smaller ones. But it also emphasises that it needs more transparency and emissions must be documented more consistently.

Summing up
Hugging Face is the main platform for distributing pre-trained ML models. Without a platform like this, most smaller AI projects would not have access to state-of-the-art models. In a way Hugging Face reflects the current trend in ML research: The field is dominated by a few actors who have the resources to train increasingly large models. However, even though training large models is restricted to actors with sufficient resources, Hugging Face enables projects with less resources to make use of these models. Moreover, even though large companies draw most attention, there is a vivid base of small- and mid-sized projects producing constant output and only small emissions.
Method & limitations
All data was scraped beginning of July 2023. As progress happens fast in ML research, the numbers might not be fully accurate already. For information on the models, Hugging Face’s own API was used. Information on the organisations was retrieved with a custom scraper. Users on Hugging Face have the option to upload information sheets, cards as they call them. These cards provide information on organisations, datasets, or models and they are the main source that informs this article. All information on organisations is self-assigned and there are a lot of empty repositories and fake-organisations. For example, while Hugging Face offers more than 260,000 models according to their search engine, only about 150,000 of these repositories are larger than ten megabytes. Since ML models require much memory, it is unlikely that these repositories actually contain models. I believe that the general trend is correct but some details might be inaccurate. The detailed information on individual organisations were retrieved manually and to the best of my knowledge.
All data can be viewed via https://github.com/SamiNenno/Inside-Huggingface
This post represents the view of the author and does not necessarily represent the view of the institute itself. For more information about the topics of these articles and associated research projects, please contact info@hiig.de.

Sami Nenno

You will receive our latest blog articles once a month in a newsletter.

Artificial intelligence and society

Prompt to perform? Sustainable talent management in the age of generative AI
What impact will generative AI have on talent pipelines? How must companies rethink their talent management?

AI between climate change and climate protection
How do climate change and artificial intelligence interact? How AI can help in the fight against climate change?

Digital by design, not by default: Resilience in higher education
What does resilience in higher education look like? A comparison of two models from Germany and Portugal shows: there is no single formula.